Pandas является отличным инструментом, когда дело касается анализа данных. Pandas построен поверх Numpy, который обеспечивает поддержку многомерных массивов. Панды могут стать плюсом, если вы добавите их в свой инструментарий Data Science toolbox. В pandas вы можете выполнить большую задачу за короткое время.
Pandas — это молниеносный инструмент, который позволяет легко выполнять задачи с большими данными. Эта библиотека включает в себя: Очистку данных, заполнение недостающих значений, нормализацию данных, статистический анализ и многое другое.
- Чтение CSV или Excel файла
- Получить заголовки всех столбцов набора данных
- Удаление лишних столбцов
- Количество строк в DataFrame
- Запрос DataFrame
- Получение подмножества значений
- df.loc()
- Вывести типы данных каждого столбца
- Статистика по набору данных
- Найти уникальные значения
- Выборка из набора данных
- Проверьте уникальные значения в столбце
- Получить все значения с Null
- Переименовать колонки
- Заполнение нулевых значений по центральной тенденции (Среднее значение, Режим, Медиана)
- Группировка
- Объединение двух DataFrame
- Способ связывания
- Найдите n наибольших и наименьших значений
- Получить информацию о DataFrame
Чтение CSV или Excel файла
Чтобы прочитать данные, хранящиеся в файле CSV, мы можем использовать команду.
df = pd.read_csv(‘Test22.csv’,sep = ‘;’)
или в файле Excel
df = pd.read_excel(‘Test22.xlsx’)
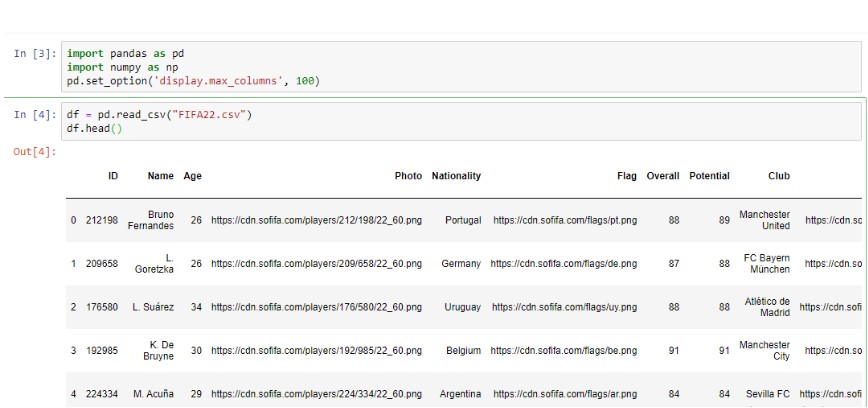
Вывод первых пяти строк
Чтобы получить доступ к первым пяти строкам набора данных, просто используйте функцию head(), и она по умолчанию вернет первые пять строк. Внутри head вы также можете установить ограничение на количество строк, к которым хотите получить доступ. например, head(10) вы получаете конкретное количество строк.
df.head( )
Получить заголовки всех столбцов набора данных
Если вы имеете дело с таким большим набором данных, как этот, имеющим более 50 столбцов, то получить все столбцы будет сложно. Для того, чтобы распечатать все столбцы данного набора данных выполним команду
df.columns

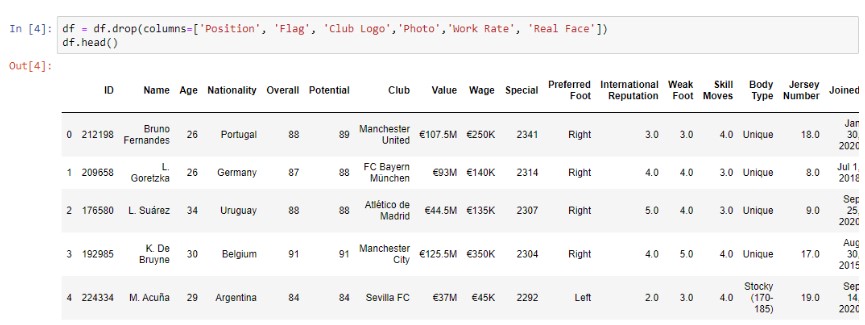
Удаление лишних столбцов
В наборе данных есть ненужные столбцы, которые вам действительно нужны. Таким образом, чтобы избавиться от ненужных столбцов, мы используем функцию.
df.drop( )
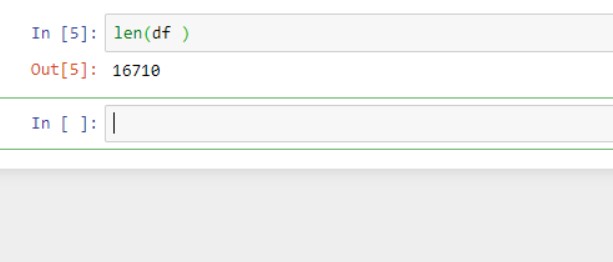
Количество строк в DataFrame
Для того, чтобы показать длину фрейма данных в наборе данных, и он вернет общее количество строк.
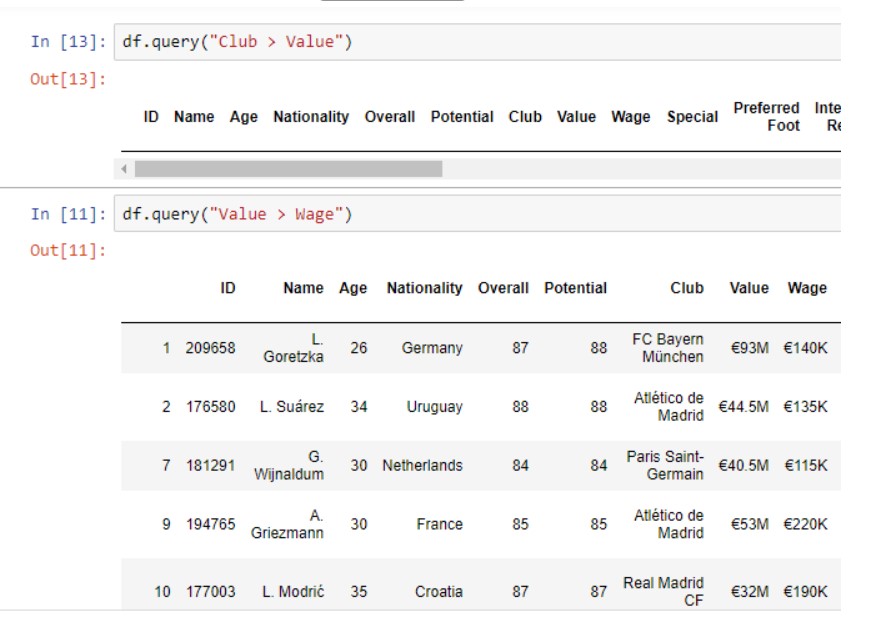
Запрос DataFrame
Вы можете фильтровать / запрашивать с помощью условного оператора. В этом примере я буду использовать столбцы «Стоимость» и «Заработная плата». Это вернет строки только в тех случаях, когда значение больше заработной платы.
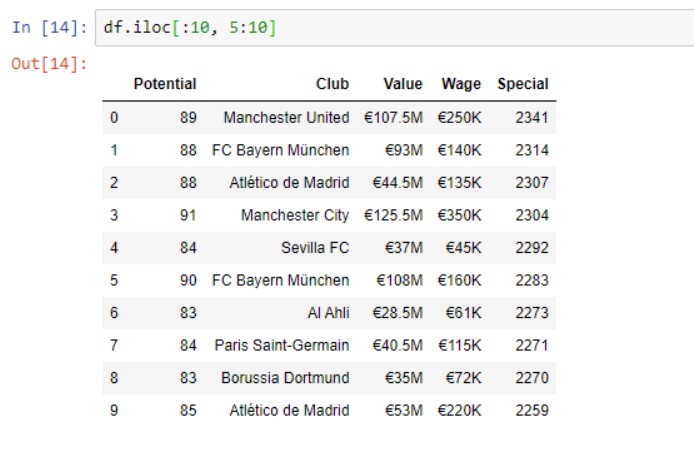
Получение подмножества значений
Функция принимает параметры индексов строк и столбцов и возвращает вам подмножество фрейма данных. Здесь мы берем первые 10 строк и индексируем 5-10 столбцов.
df.iloc[:10,5:10]
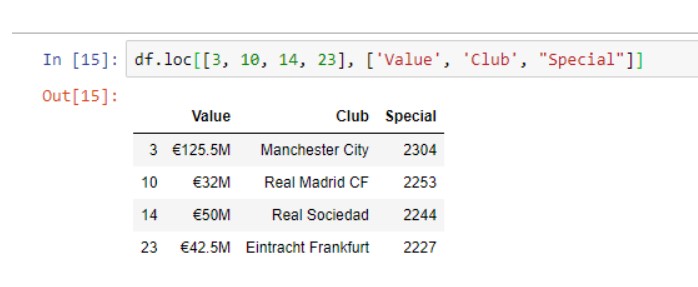
df.loc()
Эта функция выполняет почти то же самое, что и .iloc(). Здесь мы можем точно указать, какой индекс строки мы хотим, а также указать имена столбцов.
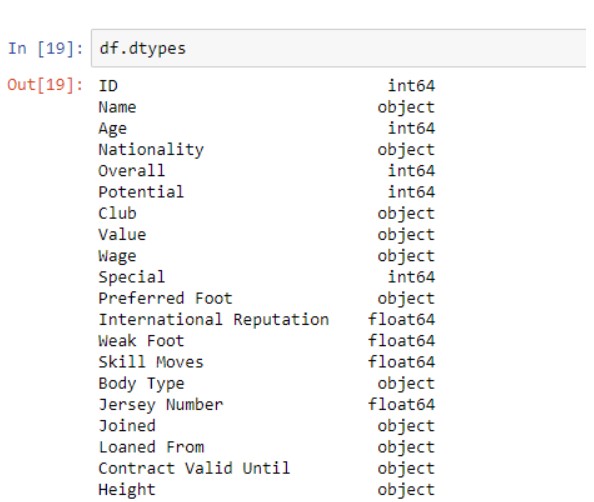
Вывести типы данных каждого столбца
Понимание характера ваших данных и типа данных каждого столбца жизненно важно для быстрого выполнения соответствующих операций при обработке данных.
df.dtypes
Статистика по набору данных
Чтобы применить функцию describe( ), она выдаст сводную или описательную статистику вашего набора данных. Эта функция будет работать только в том случае, если данные представлены в числовой форме. Для категориальных данных функция describe ( ) подсчитывает только значения в наборе данных.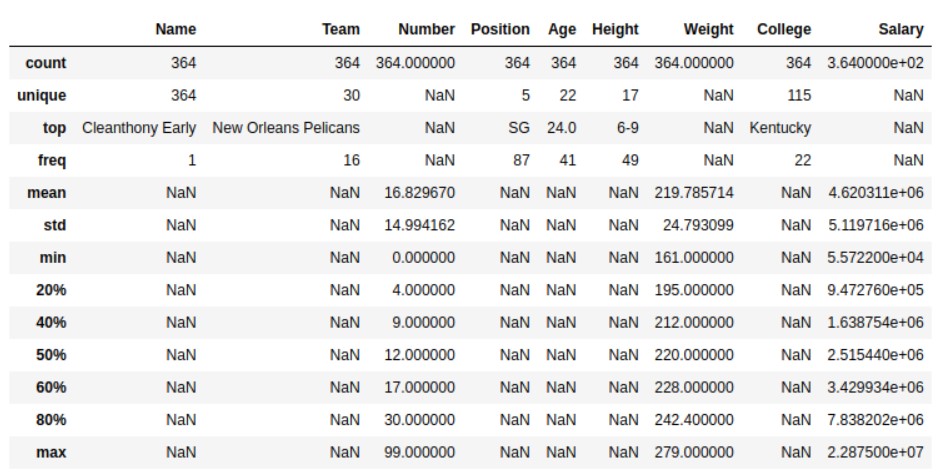
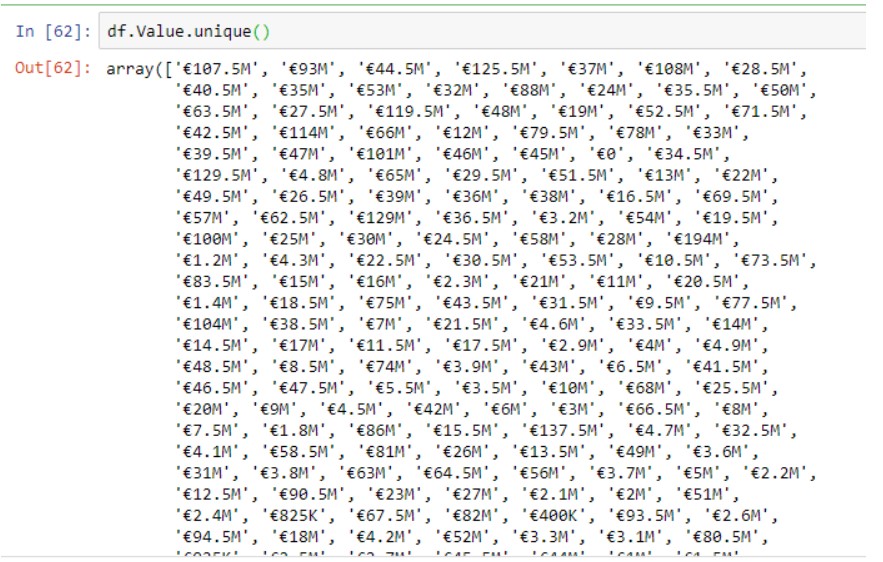
Найти уникальные значения
Это очень полезно, когда у нас есть категориальные значения. Он используется для определения уникальных значений из категориального столбца набора данных. Здесь мы применили его к столбцу “Значение” набора данных.
df.Value.unique( )
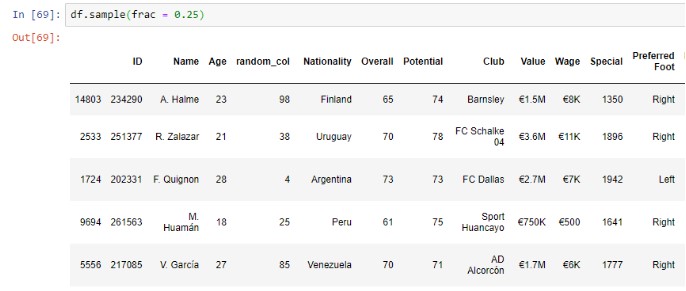
Выборка из набора данных
Когда у нас есть огромный набор данных, мы можем взять небольшую репрезентативную выборку из набора данных. Здесь я взял 25% данных в качестве выборки из набора данных. Это экономит время, повышает производительность модели и улучшает визуализацию.
df.sample(frac = 0.25)
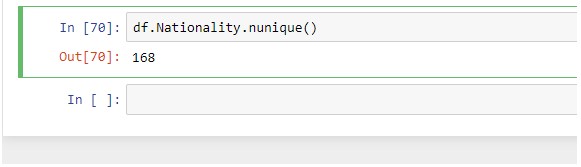
Проверьте уникальные значения в столбце
Эта функция вернет общее количество уникальных значений в определенном столбце набора данных. если вы хотите проверить, сколько там разных национальностей.
df.Nationality.nunique( )
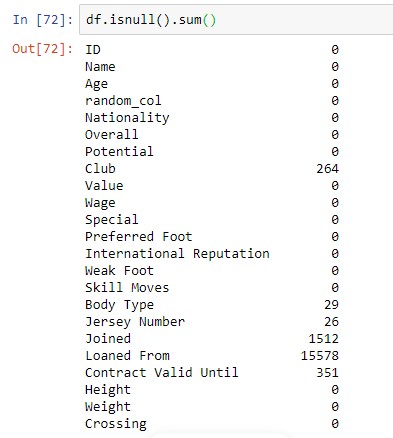
Получить все значения с Null
Чтобы проверить нулевые значения в вашем наборе данных, мы можем использовать isnull().sum(), чтобы вернуть количество нулевых значений в каждом столбце.
df.isnull().sum()
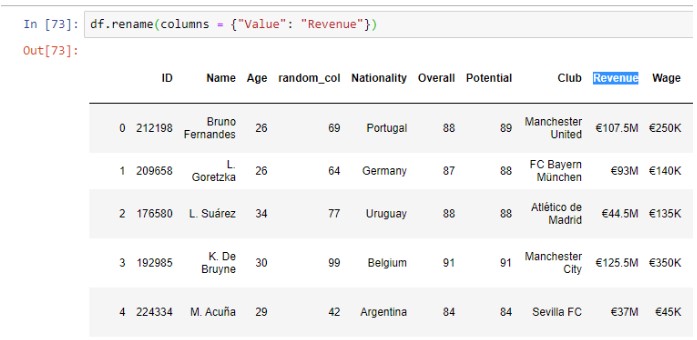
Переименовать колонки
Мы можем переименовать любой конкретный столбец из набора данных с помощью df. функция rename(). Здесь мы изменили Стоимость на Доход.
df.rename(columns = {“Value”: “Revenue”})
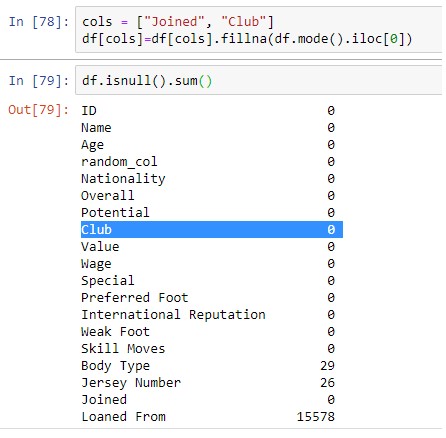
Заполнение нулевых значений по центральной тенденции (Среднее значение, Режим, Медиана)
Мы можем заполнить нулевые значения различными подходами в зависимости от типа данных, которые мы получаем. Для категориальных данных предпочтительнее использовать режим, в то время как для числовых значений мы будем использовать среднее и медиану. Здесь мы заполнили нулевые значения режимом для категориальных столбцов ‘клуб’ и ‘присоединился’.
cols = [“Joined”, “Club”]
df[cols]=df[cols].fillna(df.mode().iloc[0])
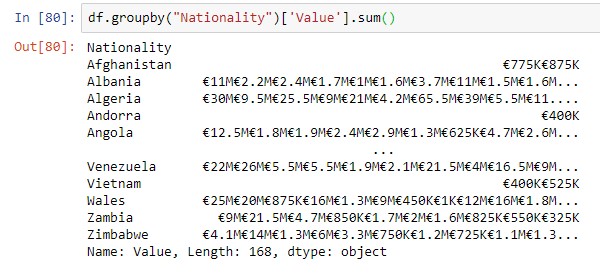
Группировка
Самая популярная функция для агрегирования данных (сводная форма). мы можем сгруппировать данные и получить полезную информацию о группах. Здесь я сгруппировал данные по национальностям и рассчитал общее ‘значение’ для каждой национальности
df. groupby(“Nationality”)[‘Value’].sum()
Объединение двух DataFrame
Объедините DataFrame или именованные объекты серии с помощью объединения в стиле базы данных.
DataFrame.merge(right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(‘_x’, ‘_y’), copy=True, indicator=False, validate=None)
Объединение выполняется по столбцам или индексам. При объединении столбцов в столбцах индексы фрейма данных будут игнорироваться. В противном случае при объединении индексов по индексам или индексов по столбцу или столбцам индекс будет передан дальше. При выполнении перекрестного слияния не допускаются спецификации столбцов для объединения.
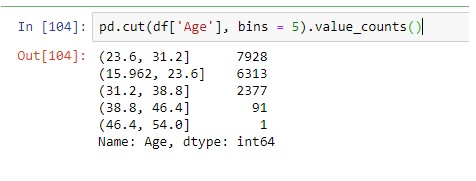
Способ связывания
Мы можем создавать ячейки для разделения данных на определенный диапазон. Метод привязки используется для нормализации данных и сглаживания их за счет удаления шума из данных. Здесь мы создали пять ячеек для данного столбца возраста, что означает разделение возраста людей на пять категорий.
pd.cut(df[‘Age’], bins = 5).value_counts()
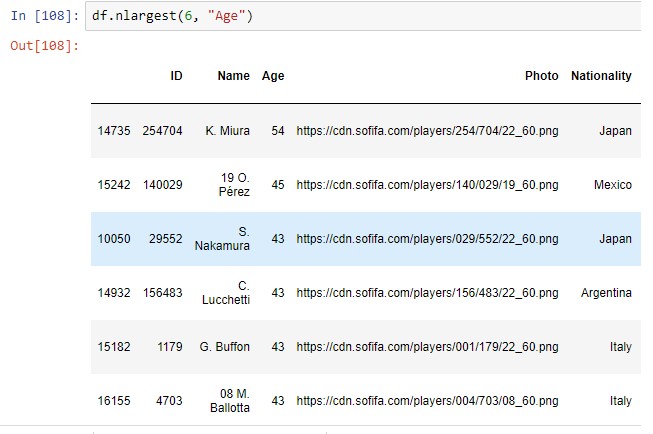
Найдите n наибольших и наименьших значений
Это дает вам данные с n числом наибольших значений или наименьших значений из заданных конкретных переменных. Здесь, например, мы хотели получить доступ к строкам с верхним номером 6 столбца возраста.
df.nlargest(6, “Age”)
df.nsmallest(6, “Age”)
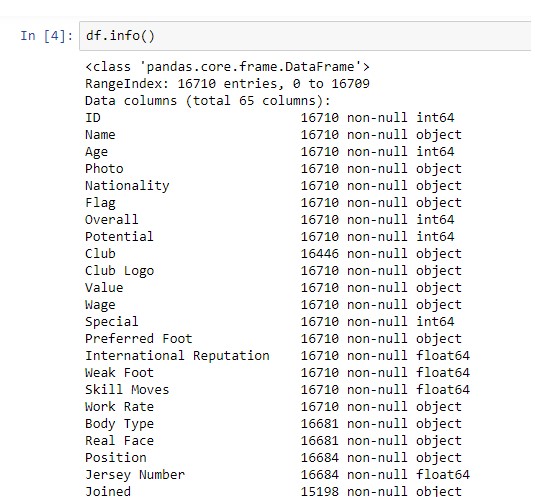
Получить информацию о DataFrame
Эта функция info() возвращает информацию о фрейме данных. Эта информация содержит количество столбцов, метки столбцов, типы данных столбцов, использование памяти, индекс диапазона и количество ячеек в каждом столбце, которые являются (ненулевыми значениями).
df.info()